Introduction to Deep Learning
This is the first course in Coursera’s Deep Learning Specialization. I will try to summarize the major topics presented in each week of each course in a series of posts. The purpose of this is to both deepen my own understanding by explaining, but also to help people who have not taken the specialization. Hopefully, these posts will inspire you to do so.
This week’s topics are:
In the most basic sense, neural networks are a particular approach to machine learning, a process in which a computer learns to perform some task by analyzing training examples. They have their not so humble origins in people trying to understand and model the human brain, particularly the way in which humans learn and store information. Learning and information representation are one of the things that make deep learning powerful. But before we get to deep learning, we need to at least define learning.
Glossing over the definition for what learning is, let’s say for now that learning amounts to being able to “reconstruct” some part of our data from the other parts (like supervised learning). Learning this reconstruction is what learning is within the context of machine learning.
So we said that neural networks are a particular approach to the machine learning problem. This approach uses a daisy-chain of building blocks called the perceptron. Think of the perceptron as a single-layer neural network.1 Deep neural networks have many such layers of perceptrons. Usually the input and output are called the input and output layers, while everything in between are called hidden layers.
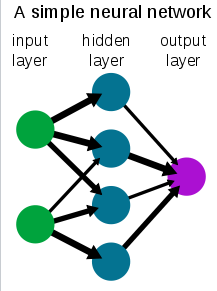
It turns out a single perceptron is not that flexible or generalizable, just like a single neuron is not that great at writing literature. However, and this is the important part, if you daisy-chain a bunch of them, and add some magic sauce (non-linearities) they are extremely generalizable. The magic of deep neural networks comes from the hidden layers. The hidden layers do something very important, which amounts to feature generation. For example if you have a dataset with some data, then the algorithm will learn how to combine the existing features into new features. And not just any features, but features that are relevant to learning the particular task. This is one of the key differences between deep learning and previous machine learning approaches. It does this by linearly combining the outputs from previous layers, down the layers, until the output layer.
Going back to learning, generally there are two main paradigms for learning (and a couple of others):
At this point it’s not terribly important to know the exact difference, other than two things. Supervised learning is so called because you use labeled data. Labeled data are pairs of features (covariates) and their associated label. Features could be the picture of a cat and the label is whether it’s a cat or not, which is called classification. You could also predict the price of a house based on a house’s features, and this is called regression. In either case explaining the performance of the algorithm is very straightforward: we are close/far from perfectly predicting (recombining) our target from the training samples. On the other hand, with unsupervised learning, there are no labels in the data, so you cannot objectively measure how the algorithm is doing based on labels. Unsupervised learning does use cost functions, but they are not usually related to the labels in the data. These are commonly clustering or partitioning algorithms. The course focuses on supervised learning.
Next week’s post is here.